Matematická olympiáda – kategorie P
Řešení úloh školního kola 54. ročníku
Komentáře k úlohám domácího kola kategorie P
Nejprve se zaměřme na to, kolika pračkami bude potřeba vybavit prádelnu. Je zřejmé, že je potřeba alespoň tolik praček, kolik má Bořivoj nejvýše v jednom okamžiku zákazníků. Později ukážeme, že tento počet praček je i dostatečný. Nejprve si však rozmysleme, jak určit maximální počet zákazníků prádelny v jednom okamžiku. Budeme simulovat dění v prádelně podle času a zároveň počítat počet zákazníků v prádelně. Událostí nazveme příchod nebo odchod některého ze zákazníků. Pro každého zákazníka si vytvoříme dvojici událostí: jednu pro příchod a druhou pro odchod zákazníka. Vytvořené události setřídíme podle jejich času a budeme sledovat příchody a odchody v pořadí, v němž jsou setříděny. Události se stejným časem zpracujeme naráz. Při odchodu snížíme počet zákazníků v prádelně, naopak při příchodu ho zvýšíme. Hledaný maximální počet zákazníků v jednom okamžiku je pak zřejmě maximum z takto získaných počtů zákazníků v prádelně.
Nyní ukážeme, že tento počet praček je dostatečný tím, že nalezneme přiřazení praček zákazníkům prádelny. Znovu spustíme simulaci příchodů a odchodů zákazníků. U každé pračky si budeme pamatovat, jestli je obsazená. V jednom okamžiku nejprve uvolníme pračky, které byly používány zákazníky, co právě odešli, a pak přiřadíme volné pračky nově příchozím zákazníkům. Zřejmě každému zákazníkovi takto přiřadíme jednu pračku a tedy počet praček je dostatečný.
Při samotné implementaci popsaného řešení ještě můžeme použít několik triků, jak náš algoritmus malinko vylepšit. Abychom se vyhnuli složitému zpracování událostí se stejným časem naráz, setřídíme události tak, že události odchodu jsou zařazeny před příchody, které nastanou ve stejný čas. Pak můžeme nejprve zpracovat odchody a poté příchody - tím zůstane korektnost algoritmu při obou simulacích zachována.
Další drobné vylepšení spočívá ve sloučení obou simulací do jedné. Začneme s prádelnou, ve které nejsou žádné pračky. Při příchodu zákazníka ho zkusíme umístit k nepoužívané pračce. Pokud žádná taková pračka neexistuje, „vytvoříme” vprádelně novou pračku, ke které zákazníka pošleme. Při odchodu zákazníka jeho pračku uvolníme. Hledaný minimální počet praček je počet praček, které jsme v prádelně museli „vytvořit” (počet praček, které existují, je roven maximálnímu počtu zákazníků, kteří byli dosud v prádelně ve stejném okamžiku).
Zbývá odhadnout časovou a paměťovou složitost našeho algoritmu.
Nejprve musíme události setřídit, na což spotřebujeme čas O(NlogN)
při použití vhodného třídícího algoritmu. Připomeňme, že N je počet
zákazníků prádelny. V implementaci jsme použili algoritmus quicksort,
který má složitost O(NlogN) sice jen v průměrném případě,
ale místo něj lze samozřejmě použít libovolný třídící algoritmus
s časovou složitostí O(NlogN) v nejhorším případě.
Poté provedeme jeden průchod setříděnými událostmi. Na zpracování jedné
události nám stačí konstantní časová složitost.
Celá simulace dění v prádelně má tak časovou složitost O(N).
Celková časová složitost našeho algoritmu je tedy O(NlogN).
Paměťová složitost je O(N), což je množství paměti potřebné na uložení zakázek,
volných a používaných praček (těch je nejvíce tolik, kolik je zákazníků) a
setříděných příchodů a odchodů do paměti.
#include <stdio.h>
#include <stdlib.h>
#define MAX_N 100
struct zakazka {
long z,t; // začátek a doba trvání
};
struct udalost {
long t; // čas události
char prichod; // příchod nebo odchod
int zakaznik; // číslo zákazníka této události
};
// porovnání udalostí: třídí se podle času a v případě shody časů nejdříve odchod
int udalost_cmp(const void *e1,const void *e2) {
if (((struct udalost *)e1)->t == ((struct udalost *)e2)->t)
return ((struct udalost *)e1)->prichod - ((struct udalost *)e2)->prichod;
return ((struct udalost *)e1)->t - ((struct udalost *)e2)->t;
}
int N;
struct zakazka zakazky[MAX_N];
int stack[MAX_N];
int stack_top=0; // index prvního neobsazeného místa v stacku
int prirazeni_pracek[MAX_N];
int pocet_pracek=0;
struct udalost udalosti[2*MAX_N];
FILE *fr,*fw;
int main(void)
{
int i;
fr=fopen("pradelna.in","r"); // načtení dat
fscanf(fr,"%d",&N);
for (i=0;i<N;i++) fscanf(fr,"%ld %ld",&zakazky[i].z,&zakazky[i].t);
fclose(fr);
for (i=0;i<N;i++) { // vytvoření událostí
udalosti[2*i].t=zakazky[i].z; // příchod
udalosti[2*i].prichod=1;
udalosti[2*i].zakaznik=i;
udalosti[2*i+1].t=zakazky[i].z+zakazky[i].t; // odchod
udalosti[2*i+1].prichod=0;
udalosti[2*i+1].zakaznik=i;
}
qsort(udalosti,2*N,sizeof(struct udalost),udalost_cmp);
for (i=0;i<2*N;i++) // simulace provozu
if (udalosti[i].prichod) {
int pracka;
if (!stack_top) /* nová pračka */ pracka=++pocet_pracek;
else pracka=stack[--stack_top];
prirazeni_pracek[udalosti[i].zakaznik]=pracka;
} else {
stack[stack_top++]=prirazeni_pracek[udalosti[i].zakaznik];
}
fw=fopen("pradelna.out","w"); // vypsání výstupu
fprintf(fw,"%d\n",pocet_pracek);
for (i=0;i<N;i++) fprintf(fw,"%d\n",prirazeni_pracek[i]);
fclose(fw);
return 0;
}
P-I-2 Závody
Tuto úlohu budeme řešit přímočaře. Budeme postupně číst čísla švábů, vždy zjistíme, kolik již doběhlo švábů s číslem vyšším, než je číslo právě zpracovávaného švába, a tento počet přičteme k výslednému počtu opačně uspořádaných dvojic. Takto zjevně započítáme každou opačně uspořádanou dvojici švábů právě jednou a získáme tedy hledanou míru promíchanosti. Pokud bychom se spokojili s kvadratickou časovou složitostí, mohli bychom počet švábů s vyšší číslem zjištovat přímým průchodem již načtených čísel. My bychom ale rádi dosáhli lepší časové složitosti, a proto musíme být chytřejší. Nadále budeme předpokládat, že N (počet švábů) je mocnina dvojky - pokud není, můžeme si snadno představit, že vstupní posloupnost je doplněna tak, aby její délka byla mocninou dvou a nic tím nezkazíme (vstup si prodloužíme nejvýše dvakrát a počet dvojic ve špatném pořadí se nezmění). Budeme si průběžně udržovat informaci, kolik dosud načtených čísel bylo vintervalu [N/2,...,N-1], kolik v intervalech [N/4,...,N/2-1] a [N/2,...,3N/4-1] a tak dále. Na počátku jsou tyto počty zjevně nulové. Když přečteme další číslo, podíváme se, zda je menší než N/2. Pokud ano, přičteme k výsledku počet čísel z intervalu [N/2,...,N-1] a pokračujeme v testování na intervalu [0,...,N/2-1]. Jinak zvýšíme počet čísel v intervalu [N/2,...,N-1] a pokračujeme v testování na intervalu [N/2,...,N-1]. Obecně na každém intervalu se podíváme, zda je nové číslo menší než střed intervalu. Pokud je, přičteme k výsledku počet čísel z horní poloviny intervalu a pokračujeme vdolní polovině. Pokud není, zvýšíme počet čísel v horní polovině intervalu o jedna a pokračujeme na ní v testování. Takto postupujeme, dokud interval nemá délku jedna. Tímto způsobem jsme dokázali zjistit počet již načtených čísel větších než aktuální číslo a zároveň jsme do naší struktury aktuální číslo zahrnuli. Protože se v každém kroku délka intervalu zkrátí na polovinu, jedno zjištění počtu větších čísel bude trvat O(logN). Celková časová složitost tedy je O(NlogN). Paměťová složitost našeho algoritmu je O(N).
Ve vzorovém programu se používá dvou ne zcela obvyklých obratů, a proto je zde alespoň stručně vysvětlíme. Zjišťování, do které poloviny intervalu aktuální číslo spadá, provádíme tak, že se podíváme na příslušný bit čísla (označme b=log2N; nejdříve testujeme b-1-tý bit, pak b-2-tý až nakonec nultý bit) a pokud je 0, číslo je v dolní polovině intervalu, pokud 1, číslo je v horní polovině. Počet čísel v jednotlivých intervalech máme uložen v poli Vetsi. Na první pozici je uložen počet čísel vjediném intervalu délky N/2 (to je interval [N/2,...,N]), na dalších dvou pozicích počet čísel ve dvou intervalech délky N/4 (to jsou intervaly [N/4,...,N/2-1] a [3N/4,...,N]), na dalších čtyřech pozicích počet čísel ve čtyřech intervalech délky N/8 atd. Intervaly stejné délky jsou vždy uspořádány vzestupně podle svých počátků. Rozmyslete si, že pokud je počet čísel v horní polovině nějakého intervalu uložen napozici i, tak počet čísel ve druhé čtvrtině tohoto intervalu je uložen napozici 2.i a počet čísel ve čtvrté čtvrtině je uložen napozici 2.i+1.
program Zavody;
const
MAXN = 8192;
IFILE = 'zavody.in';
OFILE = 'zavody.out';
var
Vetsi : Array[1..MAXN] of Integer; {Pole s počty větších prvků}
N, C : Integer; {Počet čísel; Aktuálně načtené číslo}
bits : Integer; {Nejbližší vyšší mocnina dvou od N}
Inverzi : Longint; {Počet opačně uspořádaných dvojic}
i : Integer; {Pomocná promenná}
inp, out : Text; {Vstupní a výstupní soubor}
{Spočte dosavadní počet čísel vetších než C a C zařadí}
function Zarad(C : Integer) : Integer;
var
i : Integer; {Pomocná proměnná}
pocet : Integer; {Počet vetších čísel než C}
act : Integer; {Aktuální vrchol ve stromu}
begin
pocet := 0;
act := 1;
for i := bits-1 downto 0 do
if (C and (1 shl i)) = 0 then begin {Spadá číslo do spodní poloviny?}
pocet := pocet + Vetsi[act]; {Započteme čísla z horní poloviny}
act := 2*act;
end
else begin {Číslo spadá do horní poloviny}
Inc(Vetsi[act]); {Zvýšíme počet čísel v horní polovině}
act := 2*act+1;
end;
Zarad := pocet;
end;
begin
Inverzi := 0;
Assign(inp, IFILE);
Reset(inp);
ReadLn(inp, N);
bits := 0; {Zjistíme nejbližší vyšší mocninu dvou}
while (1 shl bits < N) do
Inc(bits);
for i := 1 to (1 shl bits) do {Inicializace}
Vetsi[i] := 0;
for i := 1 to N do begin {Výpočet začíná}
Read(inp, C);
Inverzi := Inverzi + Zarad(C);
end;
Close(inp);
Assign(out, OFILE);
Rewrite(out);
WriteLn(out, Inverzi);
Close(out);
end.
P-I-3 Fylogenetika
Nejprve si zadefinujme některé pojmy a značení. Pojmy slovo a řetězec budou v následujícím textu znamenat to samé - konečnou posloupnost znaků z nějaké konečné abecedy (v našem případě `A', `C', `G' a `T'). Například AAA a GGAGCTG jsou řetězce. Speciální případ řetězce je prázdný řetězec, tj. takový, který neobsahuje žádné znaky. Budeme ho značit λ. Délka řetězce je počet znaků, z nichž se skládá. Délku řetězce v si budeme značit |v|. Tedy například |AAA|=3, |λ|=0.
Jsou-li u a v řetězce, označíme uv jejich spojení. Tedy pokud třeba u=AGG a v=CCT, je uv=AGGCCT.
Počátečnímu úseku řetězce budeme říkat jeho prefix - tedy slovo u je prefixem slova v, pokud existuje řetězec w takový, že uw=v. Koncový úsek řetězce označíme jako jeho suffix. Slovo samotné je svým prefixem i suffixem (položíme-li w rovno prázdnému řetězci). Prefix (resp. suffix) slova v je netriviální, pokud je různý od v.
Podřetězec řetězce v je libovolný souvislý úsek znaků obsažený ve v - tedy w je podřetězec v, jestliže existují (ne nutně neprázdná) slova z a k taková, že v=zwk; jinak řečeno, pokud je w suffixem nějakého prefixu slova v.
Nyní se můžeme pustit do řešení úlohy. Zadané řetězce si označme s1, s2, ..., sn. S bude součet jejich délek, tedy S=|s1|+|s2|+...+|s_n|. Ze slov si si sestavíme vyhledávací automat. Vyhledávací automat je struktura, umožňující pro libovolný řetězec t určit všechna slova si, která se vyskytující jako podřetězec v t, v lineárním čase. Když toto budeme umět, řešení úlohy je již jednoduché - tento postup provedeme postupně pro t=s1, t=s2, ..., t=s_n, čímž si zjistíme postupně předky prvního, druhého, ..., n-tého organismu. Časová složitost bude O(S + čas na konstrukci automatu + délka výstupu).
Nyní zbývá vytvořit takový automat. Vyhledávací automat se skládá ze dvou částí - trie postavené z řetězců si a takzvané zpětné funkce.
Popis trie začneme příkladem - takto vypadá trie pro řetězce ze vzorového vstupu v zadání:
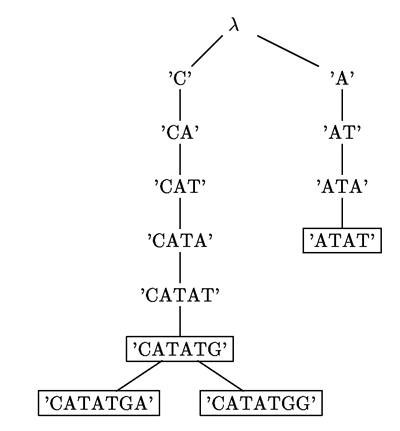
Trie je strom, jehož vrcholy odpovídají všem prefixům řetězců si. Když má několik řetězců si stejný začátek, odpovídá tomuto společnému prefixu jen jeden vrchol. Synové vrcholu odpovídajícího řetězci w jsou vrcholy odpovídající řetězcům wx, kde x je nějaký znak abecedy, v našem případě A, C, G nebo T. Každý vrchol má tedy nejvýše čtyři syny, ale může mít i méně, pokud žádné z si nezačíná na wx. Kořen stromu odpovídá prázdnému řetězci.
Některé vrcholy trie odpovídají slovům z si - například vrcholy, které nemají žádné syny, ale mohou to být i vrcholy uvnitř trie, pokud je některé zeslov prefixem jiného. Ostatní vrcholy budeme označovat jako pomocné.
O slovu budeme říkat, že je reprezentováno v trii, pokud je to jedno ze slov si, pro které jsme trii postavili. O slovu budeme říkat, že je vtrii obsaženo, pokud mu odpovídá nějaký vrchol trie (může být i pomocný). Každé slovo, které je vtrii reprezentováno, je vní samozřejmě i obsaženo, opačné tvrzení obecně neplatí. Ve zbytku textu budeme občas ztotožnovat vrcholy trie se slovy, která jim odpovídají. Budeme-li například mít funkci, která vrcholu trie odpovídajícímu slovu v přiřazuje jiný její vrchol odpovídající slovu w, budeme občas pro zjednodušení říkat, že tato funkce přiřazuje slovu v slovo w.
V každém vrcholu trie budeme mít ukazatele na jeho čtyři syny odpovídající jednotlivým písmenům. Někteří z jeho synů samozřejmě nemusí existovat, v tom případě bude příslušný ukazatel nil. Kromě toho bude vrchol obsahovat hodnotu typu boolean udávající, zda daný vrchol odpovídá nějakému slovu reprezentovanému v trii, nebo zda je pouze pomocný.
Zjistit, zda je v trii obsaženo nějaké slovo, lze snadno v čase lineárním v délce tohoto slova: Začneme v kořeni. Z něj se posuneme do syna odpovídajícího prvnímu písmenu slova, z tohoto syna dále po hraně odpovídající druhému písmenu, atd. Pokud narazíme na nil dříve, než dojdeme ke konci slova, toto slovo se v trii nevyskytuje. Až dojdeme do vrcholu, který odpovídá zadanému slovu, ještě zkontrolujeme, zda je toto slovo v trii reprezentováno, tj. zda příznak vrcholu, do kterého jsme přišli, je true.
Obdobně můžeme trii postavit - provádíme postup analogický hledání, jen ve chvíli, kdy vypadneme z trie (tj. narazíme na nil), začneme stavět novou cestu. Tento postup nám dohromady zabere čas O(S).
Dále si nadefinujeme zpětnou funkci f, která každému vrcholu trie přiřadí nějaký jiný, odpovídající kratšímu slovu (proto zpětná). Pro vrchol w bude f(w) definováno jako vrchol v takový, že v je nejdelší netriviální suffix w obsažený vtrii. Jednoduchý způsob, jak zpětnou funkci spočítat, je tedy tento: Vezmeme si slovo w a zahodíme z něj první písmeno. Pokud je takto vzniklé slovo v obsaženo v trii, je f(w) = v. Jinak z něj znovu zahodíme první písmeno a postup opakujeme, dokud hodnotu zpětné funkce neurčíme - to se určitě stane, neboť se zcela jistě zastavíme nejpozději na prázdném řetězci. Pro vzorový vstup f(ATA) = f(CA) = f(CATATGA)= A, f(ATAT) = f(CAT) = AT, f(CATA) = ATA, f(CATAT) = ATAT, f(A) = f(C) = f(AT) = f(CATATG) = f(CATATGG) = λ.
Význam funkce f je tento: Nechť máme nějaký text a chceme zjistit, která slova obsažená v trii končí na zadané pozici vtomto textu. Nechť nám navíc někdo prozradí, že s je nejdelší takové slovo. Pak f(s) je druhé nejdelší, f(f(s)) třetí nejdelší, atd., dokážeme je tedy v lineárním čase vypsat (a navíc seřazené podle délky). To se nám bude hodit, protože při hledání pomocí automatu si budeme pamatovat pro každou pozici v textu vždy právě toto slovo s (přesněji řečeno vrchol v trii, který mu odpovídá).
Výše popsaný triviální postup, jak f spočítat, by nám zabral čas O(S3) - pro každý z nejvýše S vrcholů bychom museli provést hledání řádově S řetězců, jejichž délka může být až S. Samozřejmě bychom to chtěli zvládnout rychleji. K tomu použijeme postup založený na dynamickém programování. Funkci f budeme postupně počítat od nejkratších slov k delším. Pro jednopísmenná slova je f(x)=λ. Uvažujme nyní slovo wx, kde x je jeho poslední písmeno. Označme v=f(wx). Víme, že v musí být nějaký suffix wx, tedy v končí na x (pokud není prázdné), tedy v=v'x pro nějaké slovo v', které je suffixem w. Nyní využijeme toho, co jsme si ukázali v předchozím odstavci - všechny suffixy w, které jsou obsaženy v trii, jsou f(w), f(f(w)), atd. Nás zřejmě zajímá nejdelší z nich, který se dá rozšířit o písmeno x tak, aby výsledné slovo bylo obsaženo vtrii. Algoritmus na určení f(wx) bude tedy tento:
Označme w'=f(w), tuto hodnotu již máme spočítanou. Pokud w'x je obsaženo v trii, je f(wx) = w'x, neboť w' je nejdelší suffix w v trii a tedy f(wx) nemůže být delší. Pokud w'x v trii není, vyzkoušíme w''=f(w') a takto pokračujeme, dokud buď nenalezneme hodnotu pro f(wx), nebo nedorazíme k prázdnému řetězci - pak f(wx) = λ. Testování, zda w'x je v trii, zvládneme v konstantním čase, neboť známe vrchol v trii odpovídající řetězci w'.
Jaká je časová složitost tohoto postupu? Při stanovování f pro jeden vrchol se nám může stát, že se funkcí f budeme muset vracet až S-krát, na první pohled by se tedy mohlo zdát, že časová složitost bude O(S2). Můžeme ovšem nahlédnout, že toto se nám nemůže stát příliš často: f(wx) bude jen o jedna delší, než slovo w''...', k němuž jsme dospěli při vracení se, tedy oproti f(w) může být nanejvýš o jedna delší. Na to, abychom se mohli vracet o k hladin tedy nejprve musíme udělat alespoň k kroků, v nichž se nevracíme vůbec a tedy je zvládneme v konstantním čase. Tato úvaha není zcela přesná, nicméně není obtížné ji domyslet do všech detailů. Dohromady se tedy budeme vracet nejvýše S-krát a časová složitost bude O(S).
Vraťme se ještě k motivaci pro definici funkce f. Řekli jsme si, že f(s), f(f(s)), atd. jsou všechny suffixy slova s obsažené v trii. Nijak jsme však nerozlišovali, zda se jedná o původně zadaná slova, která jsou trií reprezentována, nebo pouze o nějaké jejich prefixy - tedy pomocné vrcholy, které žádné z původně zadaných slov nereprezentují. Samozřejmě někde mezi nimi jsou i všechna ta slova, která nás zajímají, nicméně mohlo by se stát, že „balastu” okolo bude mnoho a jeho přeskakování nám zhorší časovou složitost.
Proto si ještě spočítáme funkci f', která pro vrchol v bude udávat nejdelší řetězec u různý od v takový, že u je reprezentováno v trii a dá se k němu dostat z v po zpětné funkci. Tato funkce bude dělat přesně to, co chceme - f'(v), f'(f'(v)), atd. jsou právě všechna slova z původní množiny, končící na dané pozici. Spočítat f' je snadné - postupujeme odnejkratších slov a využijeme toho, že f'(v) = f(v) pokud f(v) je reprezentováno v trii a f'(v) = f'(f(v)) jinak. Toto lze také zřejmě provést v čase O(S).
Tím jsme dokončili konstrukci automatu. Nyní zbývá ještě vysvětlit, jak takto získaný automat použít. Jak jsme řekli v úvodu, automat nám umožňuje rychle nalézt pro libovolný text všechna slova si, která jsou jeho podřetězcem. Označme si prohledávaný text t.
Pro každý počáteční úsek zadaného textu (slova) t bychom chtěli najít nejdelší suffix tohoto úseku, který je v trii obsažen (pak můžeme s použitím funkce f' snadno nalézt všechna si, která jsou suffixem libovolného počátečního úseku). Tyto suffixy postupně spočítáme pro počáteční úsek t délky 0, 1, 2, atd. Označme l(i) hledaný suffix pro úsek délky i.
Počáteční úsek t délky 0 je prázdné slovo a tedy l(0)=λ.
Nechť jsme již spočítali l pro délku i a l(i)=s. Nechť písmeno na (i+1)-ní pozici v t je x. l(i+1) má být nejdelší řetězec obsažený v trii, který se vyskytuje jako podřetězec t končící na pozici i+1, tedy l(i+1) musí končit na x. l(i+1) si tedy můžeme napsat jako rx pro nějaký řetězec r, který je také obsažen v trii. Navíc r musí to být suffix s. Projít všechny suffixy s už umíme - stačí projít s, f(s), f(f(s)), atd. Mezi nimi hledáme nejdelší, který se dá rozšířit o x tak, abychom zůstali v trii. Všimněme si, že nejdelší takový suffix musí byť první, na který narazíme.
Toto opakujeme, dokud nezpracujeme celý řetězec t. Podobný postup jsme již prováděli při konstrukci zpětné funkce, proto nás asi nepřekvapí, že i zde dosáhneme lineární časové složitosti: s se posune směrem od kořene nanejvýš |t|-krát (vkaždém kroku o jednu), tedy směrem ke kořeni se můžeme pohnout také nejvýše |t|-krát. Celková časová složitost je tedy O(t).
Pro každou počáteční úsek s textu si navíc označíme slova ze zadání, která jsou jeho suffixy. Jak jsme si již rozmysleli, jsou to právě slova f'(s), f'(f'(s)), atd., plus případně slovo s, je-li jedním ze zadaných. Chtěli bychom, aby nám navypisování výstupu stačila časová složitost O(délka výstupu). To by se nám mohlo pokazit, pokud by se nějaké slovo r vtextu vyskytovalo mnohokrát - pak totiž budeme mnohokrát zbytečně procházet posloupnost slov f'(r), f'(f'(r)), .... To snadno napravíme tak, že jakmile narazíme na označené slovo, dál se již funkcí f' vracet nebudeme - víme totiž, že všechna další slova, kekterým bychom se takto mohli dostat, jsme již vypsali, když jsme zde byli poprvé. Takto každé vypsané slovo navštívíme právě jednou, a tedy dosáhneme požadované časové složitosti.
Celková složitost řešení zadané úlohy je O(S + délka výstupu). To je zjevně optimální, protože minimálně musíme načíst vstup a vypsat výsledek. Paměťová složitost je O(S).
program Phylogenetics;
type pList = ^List; { typ pro seznam organismů }
List =
record
code : string;
organism : integer;
next : pList;
end;
type Base = (bA, bC, bG, bT);
pTrieNode = ^TrieNode; { typ pro vrchol trie }
TrieNode =
record
sons : array[Base] of pTrieNode; { větve odpovídající jednotlivým písmenům }
back : pTrieNode; { zpětná funkce }
backInSet : pTrieNode; { zpětná funkce iterovaná až k prvnímu vrcholu
reprezentujícímu organismus }
organism : integer; { číslo organismu representovaného vrcholem
nebo 0, pokud takový není }
seen : integer; { byl-li již tento organismus vypsán při
prohledávání jeho potomka, číslo tohoto potomka }
next : pTrieNode; { následující vrchol trie ve frontě }
end;
function BaseToNumber(ch : char) : Base; { převede znaky ACGT na hodnoty typu Base }
begin
case ch of
'A': BaseToNumber := bA;
'C': BaseToNumber := bC;
'G': BaseToNumber := bG;
'T': BaseToNumber := bT;
end;
end;
function BaseToChar(b : Base) : char; { převede hodnotu typu base na znaky ACGT }
begin
case b of
bA: BaseToChar := 'A';
bC: BaseToChar := 'C';
bG: BaseToChar := 'G';
bT: BaseToChar := 'T';
end;
end;
function NewTrieNode : pTrieNode; { vytvoří nový vrchol trie }
var ret : pTrieNode;
i : Base;
begin
new (ret);
for i := bA to bT do
ret^.sons[i] := nil;
ret^.back := nil;
ret^.backInSet := nil;
ret^.organism := 0;
ret^.seen := 0;
NewTrieNode := ret;
end;
{ přidá suffix řetězce S od pozice P do trie ROOT }
procedure AddToTrie(var root : pTrieNode; var s : string; p, organism : integer);
begin
if root = nil then
root := NewTrieNode;
if p > length (s) then
begin
{ jsme na konci řetězce }
root^.organism := organism;
end
else
begin
{ přidáme organismus do větve určené aktuální bazi }
AddToTrie (root^.sons[BaseToNumber (s[p])], s, p + 1, organism);
end;
end;
{ spočítá zpětnou funkci pro vrchol V trie, jehož otec je O a do v se dostaneme hranou číslo C. }
procedure ComputeBack (v, o : pTrieNode; c : Base);
var last : pTrieNode;
begin
repeat
last := o;
o := o^.back;
until (o = nil) or (o^.sons[c] <> nil);
if o = nil then
v^.back := last
else
v^.back := o^.sons[c];
if v^.back^.organism = 0 then
v^.backInSet := v^.back^.backInSet
else
v^.backInSet := v^.back;
end;
{ spočítá zpětnou funkci pro trii s vrcholem R. }
procedure ComputeBackFunction (r : pTrieNode);
var queue : pTrieNode;
queueEnd : pTrieNode;
son : pTrieNode;
c : Base;
begin
r^.back := nil;
queue := r;
queue^.next := nil;
queueEnd := queue;
repeat
for c := bA to bT do
begin
son := queue^.sons[c];
if son <> nil then
begin
ComputeBack (son, queue, c);
queueEnd^.next := son;
queueEnd := son;
queueEnd^.next := nil;
end;
end;
queue := queue^.next;
until queue = nil;
end;
{ vytvoří vyhledávací automat ze zadaného seznamu řetězců }
function CreateAutomaton (l : pList) : pTrieNode;
var root, head : pTrieNode;
i : integer;
begin
root := nil;
while l <> nil do
begin
AddToTrie (root, l^.code, 1, l^.organism);
l := l^.next;
end;
root^.back := nil;
ComputeBackFunction (root);
CreateAutomaton := root;
end;
procedure FindAncestors (o : pList; a : pTrieNode); { nalezne všechny předky organismu O }
var i : integer;
v, son : pTrieNode;
begin
for i := 1 to length (o^.code) do
begin
while (a^.back <> nil) and (a^.sons[BaseToNumber (o^.code[i])] = nil) do
a := a^.back;
son := a^.sons[BaseToNumber (o^.code[i])];
if son <> nil then
a := son;
if a^.organism = 0 then
v := a^.backInSet
else
v := a;
while (v <> nil) and (v^.seen <> o^.organism) do
begin
if v^.organism <> o^.organism then
writeln (v^.organism, ' ', o^.organism);
v^.seen := o^.organism;
v := v^.backInSet;
end;
end;
end;
{ nalezne všechny předky organismu v seznamu L }
procedure FindAllAncestors (l : pList; a : pTrieNode);
begin
while l <> nil do
begin
FindAncestors (l, a);
l := l^.next;
end;
end;
function ReadOrganisms : pList; { načte seznam organismů }
var ret, act : pList;
i : integer;
begin
ret := nil;
i := 1;
while not eof do
begin
new (act);
readln (act^.code);
act^.organism := i;
inc (i);
act^.next := ret;
ret := act;
end;
ReadOrganisms := ret;
end;
procedure DumpAuto(x : pTrieNode; indent : integer); { vypíše automat odsazený o indent mezer }
procedure ind;
var j : integer;
begin
for j := 1 to indent do write (' ');
end;
var i : Base;
begin
ind; writeln ('node ', integer(x));
ind; writeln (' organism ', x^.organism);
ind; writeln (' back ', integer(x^.back));
ind; writeln (' backInSet ', integer(x^.backInSet));
writeln;
for i := bA to bT do
if (x^.sons[i] <> nil) and (x^.sons[i] <> x) then
begin
ind; writeln (' sub ', baseToChar (i));
DumpAuto (x^.sons[i], indent + 4);
end;
end;
var organisms : pList;
automaton : pTrieNode;
begin
organisms := ReadOrganisms;
automaton := CreateAutomaton (organisms);
{ DumpAuto(automaton, 0); }
FindAllAncestors (organisms, automaton);
end.
P-I-4 ALIK
- Úlohu budeme řešit podobně jako Příklad 2 zestudijního textu postupným převáděním
nastále jednodušší problémy. Bez újmy naobecnosti budeme předpokládat, že velikost vstupu N
je mocnina dvojky (kdyby nebyla, doplníme si vstup nulami, čímž se výsledek evidentně nezmění a
N se maximálně zdvojnásobí).
Výpočet rozdělíme nafáze, přičemž nakonci i-té fáze budou bity registru y pomyslně rozděleny nabloky o 2i bitech a vkaždém bloku bude uložen počet jedničkových bitů vodpovídajícím bloku vstupu. Takové číslo se jistě do 2i bitů vejde, protože 2i > i pro každé i. Hodnotu registru y nakonci i-té fáze si označme yi.
Počáteční y0 je rovno vstupu x, protože každý bit obsahuje počet jedniček vsobě samém. Pro i=log2N dostaneme požadovaný výsledek, neboť yi se bude skládat zjediného bloku, vněmž bude uložen počet jedniček vcelém vstupním čísle. Stačí tedy vyřešit, jak z yi spočíst yi+1: Každý velký blok v yi+1 obsahuje součet dvou malých bloků poloviční velikosti v yi, které leží namístě horní, resp. spodní poloviny velkého bloku. Proto stačí posunout si vyšší zmalých bloků napozici nižšího a oba sečíst. Tomůžeme provést pro všechny velké bloky najednou následujícím programem: (bj zde značí jednotlivé malé bloky velikosti b=2i, Bj jsou výsledné velké bloky velikosti B=2b=2i+1)
p := y AND (0b1b)N/B
q := (y >> b) AND (0b1b)N/B
y := p + q
y=b0b1... bN/b-1 = y_i
p=0bb10bb3 ... 0bbN/b-1
q=0bb00bb2 ... 0bbN/b-2
y= B0 B1 ... BN/B-1 = yi+1
Jednu fázi tedy provedeme vkonstantním čase. Celý program proto proběhne včase O(logN) sregistry délky O(N).
Ukázka výpočtu pro vstup délky 8:
x=0 1 1 1 1 1 0 1 y := x y=0|1|1|1|1|1|0|1 = y0 p := y AND 01010101 p=. 1|. 1|. 1|. 1 q := (y >> 1) AND 01010101 q=. 0|. 1|. 1|. 0 y := p + q y=0 1|1 0|1 0|0 1 = y1 p := y AND 00110011 p=. . 1 0|. . 0 1 q := (y >> 2) AND 00110011 q=. . 0 1|. . 1 0 y := p + q y=0 0 1 1|0 0 1 1 = y2 p := y AND 00001111 p=. . . . 0 0 1 1 q := (y >> 4) AND 00001111 q=. . . . 0 0 1 1 y := p + q y=0 0 0 0 0 1 1 0 = y3 - Nechť zadané číslo x, kekterému máme najít nejbližší vyšší číslo y se stejným počtem jedniček,
obsahuje alespoň jednu jedničku (pokud ne, hledané y neexistuje a my můžeme vydat libovolný výsledek).
Najdeme-li v x poslední souvislý úsek jedniček (může to být ijediná jednička),
musí před ním být 0 (vopačném případě je x nejvyšší číslo sdaným počtem jedniček
a y opět neexistuje). Číslo x tedy lze zapsat vetvaru α01k0l.
Ukážeme, že hledané číslo y bude rovno číslu q=α10l+11k-1:
- q obsahuje stejný počet jedniček jako x.
- q > x - pro každá α,β,γ, kde β a γ mají stejnou délku, je totiž α1β > α0γ.
- Mezi x a q již žádné číslo se stejným počtem jedniček není - každé číslo mezi totiž musí buďto vzniknout z x zvyšením části 0l, čímž by přibyly přespočetné jedničky, nebo z q snížením části 1k-1, atehdy by jedniček příliš ubylo.
Jak ale číslo q zkonstruovat? Nejprve postupem podobným jako v Příkladu 1 spočítáme několik pomocných hodnot:
a := x - 1
b := x OR a
c := x AND a
d := b + 1
e := c XOR d
f := (e-1) AND e
x=α01k-110l
a=α01k-101l
b=α01k-111l
c=α01k-100l
d=α10k-100l
e= 11k-100l = 1k0l+1
f= 1k-10l+2
Nyní by stačilo jedničky v f posunout kpravému okraji čísla a zkombinovat sjedničkami v d a dostali bychom kýžené číslo q. Operace >> to ale sama osobě nedokáže, neboť posunutí nemáme dáno počtem bitů, nýbrž podmínkou „první jednička se dotkne okraje”.
Znovu nato půjdeme postupným zjednodušováním problému a budeme bez újmy naobecnosti předpokládat, že Nje mocnina dvojky. Fáze si tentokrát očíslujeme pozpátku: od log2N-té po nultou. V i-té fázi zařídíme, aby f končilo naméně než 2i nul. Opět vpočáteční fázi nemáme co napráci a vkoncové dostaneme očekávaný výsledek. Ostatní fáze budou fungovat takto: dostaneme f, které končí nanejvýše 2i+1 nul a potřebujeme ho posunout doprava tak, aby končilo nanejvýše 2i nul. Stačí se tedy podívat, zda je nejnižších 2i bitů nulových, a pokud ano, fposunout doprava o 2i míst. Tolze provést například pomocí konstrukce r:=if(s,t,u) z Příkladu2:
g := f AND 12^i
h :=if(g, 0, 2i)
f :=f >> h
g=dolních 2i bitů fi+1
h=okolik posouváme
f=výsledek i-té fáze fi
Poposlední fázi zakončíme:
y :=d OR f
d=α10k-100l
f= 00l+11k-1
y=α10l+11k-1
a jsme hotovi. Trvalo nám to celkem O(logN) kroků (konstantně mnoho nainicializaci, nakonečný výpočet y a rovněž nakaždou fázi), potřebovali jsme registry o O(N) bitech.
Příklad výpočtu pro N=8:
a := x - 1
b := x OR a
c := x AND a
d := b + 1
e := c XOR d
f := (e-1) AND e
g := f AND 00001111
h := if(g, 0, 22)
f := f >> h
g := f AND 00000011
h := if(g, 0, 21)
f := f >> h
g := f AND 00000001
h := if(g, 0, 20)
f := f >> h
y := d OR f
x=10111000
a=10110111
b=10111111
c=10110000
d=11000000
e=01110000
f=01100000 = f3
g=....0000
h=00000100
f=00000110 = f2
g=......10
h=00000000
f=00000110 = f1
g=.......0
h=00000001
f=00000011 = f0
y=11000011