Matematická olympiáda – kategorie P
Řešení úloh školního kola 50. ročníku
Tento pracovní materiál není určen primárně přímo studentům - účastníkům olympiády. Má pomoci učitelům na školách při přípravě konzultací a pracovních seminářů pro řešitele soutěže, členům oblastních výborů MO slouží jako podklad pro opravování úloh domácího kola MO kategorie P. Studentům je možné tyto komentáře poskytnout až po termínu stanoveném pro odevzdání řešení úloh domácího kola MO kategorie P jako informaci, jak bylo možné úlohy správně řešit, a pro jejich odbornou přípravu na účast v oblastním kole soutěže.P-I-1 Stromy
Je jasné, že za každé dva uzly hloubky K, K>0 musí existovat jeden uzel hloubky K-1, který není listem - každé dva uzly musíme pod nějaký uzel "zavěsit". Protože navíc pod každý uzel můžeme zavěsit pouze žádný nebo dva uzly, musí být počet uzlů hloubky K sudý. Výše uvedená pozorování nám již dávají návod na sestrojení algoritmu. Pro každou hloubku si budeme pamatovat počet listů a počet ostatních uzlů. Budeme postupovat od uzlů s největší hloubkou. Pro každou hloubku K, K>0 zkontrolujeme, zda je počet uzlů v ní sudý. Pokud není, strom neexistuje. Pokud je počet uzlů sudý, za každé dva uzly umístěné ve stromu na dané hloubce přidáme do předchozí hloubky jeden uzel. Když se takto dostaneme až k uzlům hloubky 0, stačí ověřit, jestli v této hloubce leží právě jeden uzel, jak je vyžadováno v definici binárního stromu. Pokud není, strom neexistuje. To plyne z toho, že pokud neexistuje uzel hloubky 0, nebyl dán žádný list, a tedy strom nemůže mít žádné uzly. To je ale ve sporu s požadavkem, že každý strom musí mít alespoň kořen. Pokud je uzlů hloubky 0 naopak více, strom neexistuje, protože všechny uzly, které jsme přidávali, byly vynucené a každý strom s danými počty listů tedy musí mít na jednotlivých hloubkách alespoň tolik uzlů jako náš strom. Pokud existuje právě jeden uzel hloubky 0, snadno již ze spočítaných počtů listů a ostatních uzlů v jednotlivých hloubkách vytvoříme požadovaný zápis stromu. Jednoduše vypíšeme tolikL, kolik je počet listů dané
hloubky, a tolik U, kolik je počet ostatních uzlů dané hloubky.
Algoritmus má časovou i paměťovou složitost O(N). Program
je přímou implementací algoritmu.
P-I-2 Posel
Algoritmus řešící tuto úlohu se dá rozdělit do tří fází. V první fázi se pro každé město spočítá, jaká je jeho vzdálenost od nepřítelem obsazených měst (ve smyslu definice uvedené v zadání). Ve druhé fázi se zjistí, jakou maximální vzdálenost od nepřátelských měst dokážeme udržet při cestě z počátečního do cílového města. Ve třetí fázi pak nalezneme nejkratší z tras vedoucích z počátečního do cílového města, které udržují spočtenou vzdálenost.První fáze: Vzdálenost od obsazených měst budeme hledat pomocí prohledávání do šířky. U každého města si budeme udržovat informaci, zda jsme v něm již byli (na počátku bude nastaveno právě u všech obsazených měst) a jeho vzdálenost od nepřítele. Pro města obsazená nepřítelem bude tato vzdálenost rovna 0. Dále si budeme udržovat frontu měst ke zpracování, do které na začátku uložíme všechna nepřátelská města. V každém kroku výpočtu vždy vezmeme jedno město z fronty a u všech jeho sousedů, ve kterých jsme dosud nebyli, nastavíme vzdálenost o jedna větší, než je vzdálenost vybraného města. U všech těchto sousedů také označíme, že jsme v nich už byli, a přidáme je na konec fronty. První fáze výpočtu končí, když se vyprázdní fronta. Tehdy jsme prošli všechna města a určili jsme vzdálenost každého z nich od nepřítele.
Druhá fáze: V této fázi si budeme udržovat front hned několik, pro každou vzdálenost od nepřátelských měst jednu. Dále si pro každé město budeme zaznamenávat, zda jsme v něm už byli. Také si budeme pamatovat dosud největší nalezenou vzdálenost, kterou dokážeme udržet od nepřítele. Na začátku nastavíme udržitelnou vzdálenost od nepřítele na hodnotu vzdálenosti královského města od nepřítele a toto město vložíme do fronty pro příslušnou vzdálenost. U tohoto města také nastavíme, že jsme v něm už byli. Výpočet probíhá tak, že postupně vyzvedáváme města z fronty pro aktuální udržitelnou vzdálenost, dokud se tato fronta nevyprázdní. Když se fronta vyprázdní, snížíme udržitelnou vzdálenost o jedna a opět začneme vybírat města z příslušné fronty. Vždy, když vezmeme nějaké město z fronty, projdeme všechny jeho sousedy, u dosud nenavštívených z nich nastavíme příznak, že už jsme je nenavštívili, a přidáme je do fronty - jestliže je vzdálenost takového města od nepřátelských měst větší, než je aktuální udržitelná vzdálenost, přidáme vrchol do fronty odpovídající aktuální udržitelné vzdálenosti, jinak město přidáme do fronty odpovídající jeho vzdálenosti od nepřátelských měst. Druhá fáze končí, jakmile vybereme z fronty cílové město. Aktuální udržitelná vzdálenost je pak výslednou udržitelnou vzdáleností.
Třetí fáze: Tato fáze představuje opět prosté prohledávání do šířky. Pro každé město si pamatujeme, zda jsme v něm již byli, a pokud ano, zaznamenáme si také město, ze kterého jsme do něj přišli. Opět používáme frontu na dosud nezpracovaná města. Na začátku vložíme do fronty cílové město. U něj nastavíme, že jsme v něm již byli, a jako jeho předchůdce nastavíme je samé. V každém kroku výpočtu pak vezmeme jedno město z fronty a projdeme všechny jeho sousedy. Každého souseda, kterého jsme dosud nenavštívili a jehož vzdálenost od nepřátelských měst je větší nebo rovna výsledné udržitelné vzdálenosti, označíme jako navštíveného a přidáme ho na konec fronty. Také u něj jako město, ze kterého jsme přišli, nastavíme právě vybrané město. Prohledávání končí ve chvíli, když je z fronty vyzvednuto počáteční (královské) město. Poté už jenom projdeme cestu z počátečního do cílového města (to je velmi snadné díky odkazům na města, odkud jsme do nich při prohledávání přišli) a cestu vypíšeme.
Algoritmus má časovou složitost O(M+N), kde M je počet cest a N je počet měst.
Správnost algoritmu budeme ukazovat opět po fázích. To, že algoritmus spočte správně vzdálenosti od nepřátelských měst v první fázi, plyne z následujícího: Na počátku mají všechny vrcholy se vzdáleností nula tuto vzdálenost přiřazenu. V okamžiku, kdy jsou zpracovány všechny vrcholy vzdálenosti nula, prošli jsme všechny jejich sousedy, přiřadili jsme jim vzdálenost jedna a zařadili je do fronty. Protože jiné vrcholy vzdálenost jedna mít nemohou, je vzdálenost jedna přiřazena právě všem správným vrcholům. Tuto úvahu lze snadno zobecnit pro libovolnou vzdálenost D. Prohledávání tedy skutečně určí vzdálenosti od nepřátelských měst správně.
Ve druhé fázi se správně spočítá maximální udržitelná vzdálenost od obsazených měst. Sledujeme v ní totiž souběžně všechny možné trasy vedoucí z počátečního města tak dlouho, dokud dokážeme udržet vzdálenost počátečního města (výsledná vzdálenost od nepřítele zřejmě nemůže být větší než vzdálenost počátečního města). Když už neexistuje město s dostatečně velkou vzdáleností, do kterého bychom mohli jít, snížíme udržitelnou vzdálenost o jedna. Všechny vrcholy se vzdáleností o jedna nižší, do kterých se dokážeme dostat přes vrcholy s dosavadní udržitelnou vzdáleností, máme již připraveny v příslušné frontě a začneme tedy prohledávat z nich. Protože udržitelnou vzdálenost snižujeme až když jsme se již dostali všude, kam to bylo možné, její výsledná hodnota bude zřejmě nejvyšší možná.
To, že ve třetí fázi nalezneme nejkratší trasu s danou vzdáleností, je zřejmé. Provádíme totiž jednoduché prohledávání do šířky s tím, že ignorujeme města s příliš malou vzdáleností od nepřítele. Nalezneme tedy určitě trasu s dostatečnou vzdáleností od nepřítele. Skutečnost, že to bude trasa nejkratší možná, plyne z vlastností prohledávání do šířky uvedených v první části důkazu.
Program je přímou implementací uvedeného algoritmu.
P-I-3 Výlet
Řešení úlohy rozdělíme na několik částí - nejprve zformulujeme nutné a postačující podmínky pro to, aby skupina mohla projet trasu dle podmínek v zadání úlohy, poté vyřešíme úlohu a) a nakonec nalezneme řešení úlohy b).Plánovanou trasu lze projet právě tehdy, když tato trasa není delší než vzdálenost, kterou skupina urazí za den, tj. L<=K, anebo když jsou splněny zároveň všechny čtyři následující podmínky:
- Na trase je alespoň jeden kemp.
- Vzdálenost prvního kempu od začátku trasy je nejvýše K, tj. l1<=K.
- Vzdálenost libovolných dvou po sobě následujících kempů není větší než K, tj. li+1-li<=K pro 1<=i<=N-1.
- Vzdálenost posledního kempu od konce trasy je nejvýše K, tj. L-lN<=K.
Nyní vyřešíme úlohu a). Na chvíli si představme, že jsme každému kempu přiřadili číslo di, které udává, kolikátý den nejdříve můžeme do tohoto kempu dorazit. Číslo di přiřazené kempu i zřejmě splňuje jednu z následujících dvou podmínek:
- Buď je di=1 a li<=K - do kempu lze dorazit hned první den.
- Existuje j<i takové, že li-lj<=K a dj=di-1 (do i-tého kempu dorazíme tak, že den před tím přespíme v j-tém kempu), ale neexistuje j<i takové, že li-lj<=K a dj<di-1 (jinak by bylo možné do j-tého kempu dorazit již dříve).
Dále vyřešíme úlohu b). Každému kempu přiřadíme číslo ei, které udává, kolik by cyklisté museli zaplatit za přespání na cestě z i-tého kempu na konec výletu (počítáno včetně poplatku za přespání v i-tém kempu). Čísla ei náš algoritmus spočítá postupně pro i=N až i=1; kromě těchto čísel, si pro každý z kempů uložíme informaci, do kterého následujícího kempu se z něj máme vydat, abychom za noclehy zaplatili optimální cenu ei. Čísla ei lze spočítat podle následujícího předpisu:
- Pokud L-li<=K, potom ei=ci; z i-tého kempu lze dorazit na konec trasy během jednoho dne.
- Pokud L-li>K, potom ei=minj (ci+ej)=ci+minj ej, kde se minimum počítá přes všechna j>i taková, že lj-li<=K; to j, pro které se nabývá minima, určuje pořadí kempu, ve kterém přespíme ten den, kdy vyjedeme z i-tého kempu.
K rychlému nalezení indexu j, použijeme datovou strukturu, která se nazývá halda. Halda je datová struktura, která umožňuje v konstantním čase určit nejmenší z prvků v haldě; prvek do haldy přidat nebo vyjmout nejmenší prvek umí v čase logaritmickém v počtu prvků obsažených v haldě. V haldě si budeme udržovat čísla kempů setříděná podle hodnot ei; na začátku budeme mít v haldě navíc konec trasy, jehož hodnotu budeme považovat za rovnu nule (bude nejmenším prvkem haldy). Nalezení vhodného j bude probíhat následovně: Zjistíme, zda nejmenší prvek haldy je od i-tého kempu vzdálený nejvýše o K - pokud ano, nalezli jsme příslušné j, v opačném případě z haldy odstraníme tento prvek a celý postup zopakujeme. Poté do haldy přiřadíme i-tý kemp. Za předpokladu logaritmického času přidání prvku do haldy a vyjmutí nejmenšího prvku z haldy je celková doba běhu algoritmu O(N log N).
Haldu budeme reprezentovat v poli. Bude-li v haldě n prvků, pak její prvky budou uloženy v poli na pozicích s čísly 0 až n-1. Pro prvek x s indexem k budeme prvky na pozicích 2k+1 a 2k+2 nazývat syny prvku x a prvek x budeme nazývat otcem těchto prvků. Všimněte si, že každý prvek, mimo prvku na pozici 0, má právě jednoho otce. Při práci s haldou budeme dodržovat následující invariant: Každý prvek je větší než jeho otec. Nejmenším prvkem v haldě je proto prvek na nulté pozici; zjištění nejmenšího prvku haldy lze tedy provést v konstantním čase. Přidání prvku do haldy bude probíhat následovně: Je-li v haldě n prvků, pak nový prvek umístíme na pozici n; pokud je jeho otec větší, vyměníme přidávaný prvek s jeho otcem a celý postup opakujeme tak dlouho, dokud nový prvek není nultým prvkem nebo jeho otec není menší než on. V každém kroku se index nového prvku v poli zmenší alespoň na polovinu a tedy se po logaritmicky mnoha krocích zastavíme. Odebrání prvku z haldy bude probíhat podobně: Je-li v haldě n prvků, pak nejmenší prvek haldy nahradíme prvkem z (n-1)-té pozice; tento prvek porovnáme s oběma jeho syny a popřípadě ho zaměníme s menším z obou jeho synů. Skončíme, pokud je tento prvek menší než oba jeho synové. Protože se v každém kroku posuneme na prvek s alespoň dvojnásobným indexem, odebrání nejmenšího prvku z haldy bude trvat čas logaritmický v počtu prvků v haldě.
P-I-4 Dlaždice
- Mějme zadáno nějaké dvojkové číslo <x1,...,xn>,
o němž máme rozhodnout, zda je dělitelné pěti.
Sestrojíme sadu dlaždic, jíž bude možno vydláždit pouze
zeď o jednom řádku, a to tak, aby barva pravé hrany i-té dlaždice
(tu budeme značit pi) odpovídala zbytku po dělení dvojkového čísla <x1,...,xi> pěti.
Když navíc zvolíme barvu pravého okraje zdi tak, aby odpovídala
zbytku 0, půjde zeď vydláždit právě tehdy, je-li zadané číslo
dělitelné pěti, a to je přesně to, co potřebujeme.
Použijeme dlaždice následujících typů:
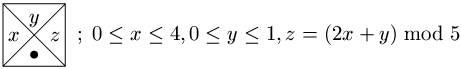
Levý i pravý okraj budou mít barvu 0 a dolní okraj barvu "kolečko". Jelikož barva "kolečko" se nevyskytuje na horní hraně žádné dlaždice, musí být každé korektní vydláždění tvořeno jediným řádkem. Zbývá dokázat, že barvy pravých hran dlaždic odpovídají zbytkům, což učiníme indukcí:- p1=<x1>=<x1> mod 5 (existuje právě jedna dlaždice, která může být na prvním políčku - ta, která má na levém okraji nulu a na horním okraji x1).
- Je-li pi=<x1,...,xi> mod 5, může být na i+1-ním políčku pouze jediná dlaždice (mající na levém okraji pi a na horním okraji xi+1) a její pravý okraj má barvu pi+1=(2pi+xi+1) mod 5= (2(<x1,...,xi> mod 5)+xi+1) mod 5= (2<x1,...,xi>+xi+1) mod 5 =<x1,...,xi+1> mod 5.
- Použijeme následující typy dlaždic:
- "Levé" dlaždice:
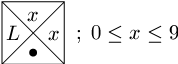
- "Pravé" dlaždice:
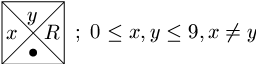
- "Opakovací" dlaždice:

Z toho, jak jsme si typy dlaždic nadefinovali, ihned plyne, že každé vydláždění zdi musí vypadat takto:

Zleva doprava: nejprve (možno i prázdná) posloupnost dlaždic opakujících L, pak jedna levá dlaždice, následuje opět několik opakovacích dlaždic, jedna pravá dlaždice a případně opakování R. Takové vydláždění je ovšem korektní právě tehdy, bylo-li možné nalézt indexy i a j takové, že xi<>xj (díky definici barev hran pravé dlaždice), takže náš dlaždicový program řeší zadanou úlohu se složitostí O(1). - "Levé" dlaždice:
Poznámka
Naše řešení využívá toho, že dlaždicové programy jsou nedeterministické (to znamená, že nemají pevně definovaný průběh výpočtu a místo toho připouštějí více různých výpočtů s tím, že odpovědí programu jeano, pokud existuje alespoň jeden korektní výpočet) a že nám
nedeterminismus "uhodne" polohu nějakých dvou různých prvků vstupní
posloupnosti.